机器学习笔记
前言
学习一下机器学习和深度学习,一可以拓展我的认知和对这种前沿技术的了解,二也是因为参加比赛的需求。我学习deep learning和machine learning是通过CS230和李宏毅机器学习。
在这里浅讲一下我对李宏毅的机器学习的认知,我看的是啥都生UP主上传的视频,该组视频我认为应该要分开看,先把2021标头的看了,这样看的连贯性会好一些,然后拓展也是需要看的。至于CS230我也看一些,讲解的比较简短,但总的来说还是全面并精准的,但是由于是英语(本人一听英文就犯困,难绷),所以最后还是去看了李宏毅老师的视频。
这段仅是个人的理解。
机器学习基本概念
基础定义
定义带有未知数的函数
定义loss函数,输入b,w。该函数的输出值为所拥有的训练集
这些函数是机器自己找出来的,需要自己设定hyperparameters(超参数),期间需要反复移动W。有俩种情况下,会停止一定w
- 达到了调整次数设定的上限
- 微分算出来的值刚刚为0
local minima和global minima。在进行gradient descent(梯度下降法)时候会存在一定的local minima的问题

都需要分别减去learning rate,反复进行更新,找到最优的w和b
以上三个步骤组合起来称为训练。现在是在答案已知的资料上去计算Loss,但真正的重点是预测未来未知的观看次数。
像这种Feature*weight+Bias就得到预测结果的Model统称为Linear model(线性模型)
但是现实生活的情况不可能只是一条直直的线,但是无论如何调整Model中的参数,都无法用Linear的Model制造复杂折线。这属于来自Model的限制,称为Model的Bias,也就是指模型无法模拟真实情况。
因此我们需要对Model进行改进,需要一个更加复杂、灵活的,并带有未知参数的Function。
复杂的曲线,更像是一个常数,再加上一堆不同的函数,称为Piecewise Linear 的 Curves。曲线的转折越多越复杂,所需要的函数就越多
所以只要有不同的 w 不同的 b 不同的 c,你就可以制造出不同的 Sigmoid Function。把不同的 Sigmoid Function 叠加起来以后,就可以去逼近各种不同的Piecewise Linear 的 Function,然后 Piecewise Linear 的 Function,可以拿来近似各种不同的 Continuous 的 Function。
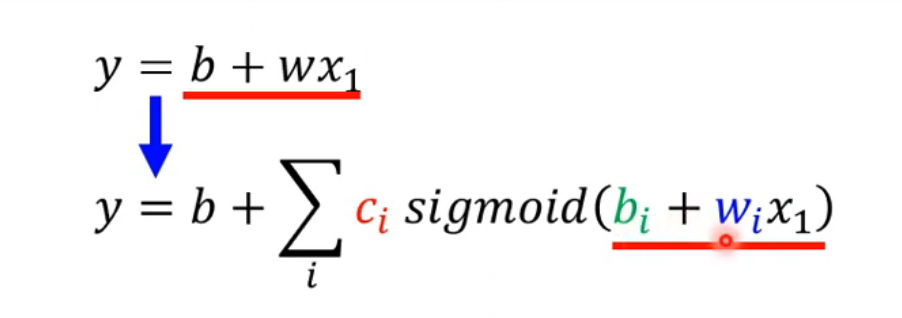
这样能使的写出更加有弹性的函数
优化
x是Feature,W是权重组成的矩阵,绿色框的b为向量,灰色框的b为数值,c为常数组成的向量。那么W c 向量b 常数b就是Unknown Parameters,也就是未知的参数

第二步就是要为这个新的Function定义一个新的Loss。
与之前Linear Model的Loss的定义的方法相同,由于这次参数变多了,就直接用θ来统设所有的参数,则Loss Function就可表示成L(θ)
最后一步进行优化,首先给定一组θ的值,然后把Feature带入,查看y和真实的label之间的差距,把所有的误差相加,就可以得到loss了。我们需要找到一组θ,使得loss越小越好
先由θ0计算Gradient(梯度),根据得到的梯度将θ0更新为θ1;之后再根据θ1计算新的Gradient,再把θ1更新为θ2……以此类推,直到计算次数达到了预先指定的上限;或者计算出来的梯度为0向量,让你无法再更新参数为止

在实际操作中,如果手中有N个数据,一般会将N个数据分成一个个的Batch,计算LOSS时只拿一个batch中的Data计算Loss,设为L1,根据这个 L1 来算 Gradient,用这个 Gradient 来更新参数。再选用下一个batch算出L2,再算出对应的Gradient,再用这个Gradient更新参数….
所以我们并不是拿L来算Gradient。实际上我们是拿一个 Batch算出来的L1 L2 L3来计算 Gradient,那把所有的 Batch 都看过一次,叫做一个Epoch,每一次更新参数叫做一次 Update。
一个Hard Sigmoid可以看作Hard Sigmoid,可以看作两个Rectified Linear Unit(ReLU 修正线性单元)的结合,使用不同数量的ReLU得出的结果有一定的差别,重复的次数又是一个Hyper Parameter,重复的次数也是由人所决定的
总结(定义)
Model中的Sigmoid或ReLU称为Neuron(神经元) ,多个神经元连起来就是Neural Network(神经网络)
图中每一层的神经元称为hidden layer(隐藏层);多个Hidden Layer就组成了Deep;以上的整套技术就称为Deep Learning(深度学习)
深度学习的层数也不能太多,太多会导致Overfitting(过拟合),也就是在训练集上表现的好,但是在测试集上表现差。
Colab(工具)
Colab = Colaboratory(即合作实验室),是谷歌提供的一个在线工作平台,用户可以直接通过浏览器执行python代码并与他人分享合作。Colab的主要功能当然不止于此,它还为我们提供免费的GPU。熟悉深度学习的同学们都知道:CPU计算力高但核数量少,善于处理线性序列,而GPU计算力低但核数量多,善于处理并行计算。在深度学习中使用GPU进行计算的速度要远快于CPU,因此有高算力的GPU是深度学习的重要保证。由于不是所有GPU都支持深度计算(大部分的Macbook自带的显卡都不支持),同时显卡配置的高低也决定了计算力的大小,因此Colab最大的优势在于我们可以“借用”谷歌免费提供的GPU来进行深度学习。
Pytorch
可以使用自己的GPU进行加速,很多都是基于Pytorch环境做的实验。
PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速,同时还支持动态神经网络。
Pytorch的安装
cmd输入nvidia-smi,查看CUDA版本号
到pytorch官网找到对应版本的命令行语句
使用anaconda配置虚拟环境为py37
执行pytorch官网找到对应版本的命令行语句
检查安装的包中有pytorch和cudatoolkit,并且确保pytorch不是CPU版本
检查是否完成安装
1
2
3
4
5import torch
//如果没有报错则导入成功
print(torch.cuda.is_available())
//输出true则为CUDA版本
2
用θ来代表这个Model裡面所有的未知函数,也就是说这个Model代表的意思是:现在有一个function叫f(x),它里面面有一些未知的参数,这些未知的参数表示成θ,它的input叫做x,同时这个input叫做feature(特征)
Model Bias(模型偏差)
Optimization Issue(优化问题)
所谓的model bias意思是说,你的model太过简单。model不具备足够的弹性。在function set(函数集)中没有一个Function可以让Loss变低。在这种情况下就需要重新设计一个model
所谓的Optimization Issue,我们一般用的optimization的方法一般gradient descent,这种方法有很多的问题。
举例来说 你可能会卡在local minima的地方,你没有办法找到一个真的可以让loss很低的参数。
gradient descent是解一个optimization的问题,找到θ* 然后就结束了。但是它给我的loss不够低。这一个model裡面,存在着某一个function,它的loss是够低的,gradient descent没有找到这一个function。
训练集的loss小,测试集的loss大,则可能是遇到了overfitting的问题了。
最简单的解决overfitting的方法就是增加训练资料。
也可以使用Data agurement。
所谓的Data augmentation就是你用一些你对于这个问题的理解,自己创造出新的资料
全周期深度学习应用程序
- 选择问题
- 应用监督学习,获取标记数据
- 设计模型
- 训练模型
- 测试
- 部署
- 维护
Batch
batch size=n,更新参数需要看完n笔资料。
不使用batch的方式是看完所有的batch再进行一次更新,使用batch则是每次输入一笔资料就进行一次更新。
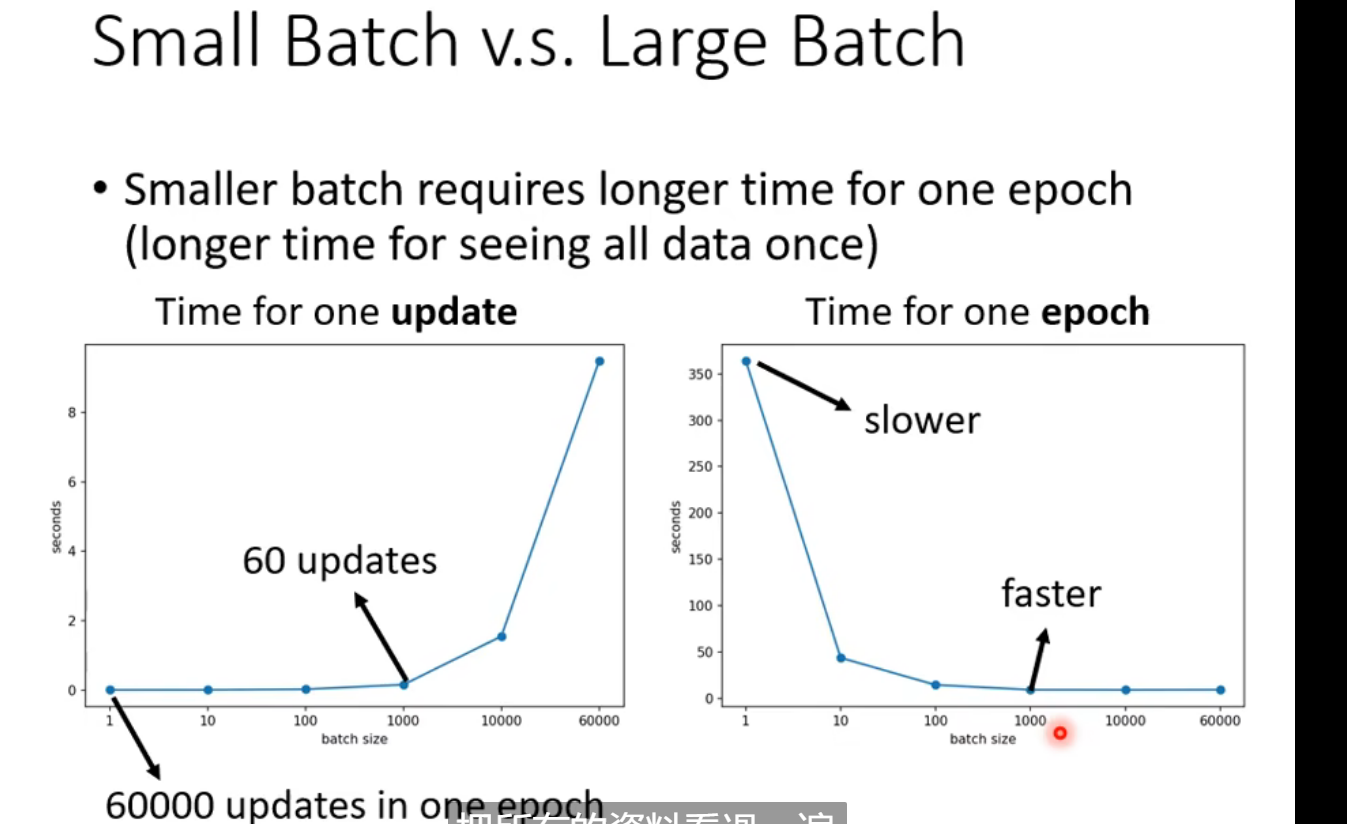
在考虑平行运算的情况下一个epoch大的batch花的时间反而比较少。
当时large batch时优化可能会较差,small batch(noisy update)对于训练的效果更好一些
small batch 和 large batch差距如图
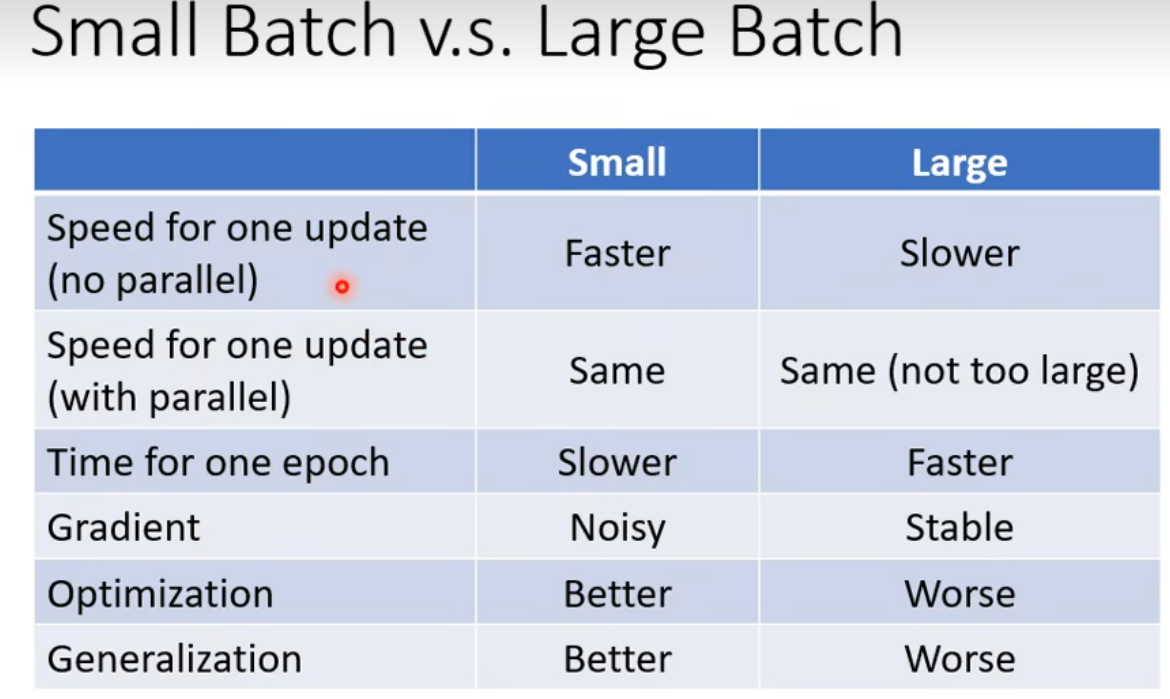
需要调整对应的超参数。
Momentum(动量梯度下降法)
Yolov5
首先需要完成pytorch的配置(CUDA版本)
github下载yolo并导入,并且设置编译器为对应的版本,然后导入需要的包
1 | |
然后下载 yolov5s.pt 权重文件。
一般来说这样就可以运行了
如果需要检测视频则需要对parse_opt函数进行修改:
1 | |
开启摄像头检测,将代码改成 default=‘0’,便可开启自带摄像头
将代码改成 default=‘1’,便可开启 USB 摄像头,进行动态的实时检测
遇到的一些问题
cv2无法导入
pip install opencv-python
要在使用的环境中执行(我就是没在使用的环境中进行,然后导致后面其他的问题 )
Couldn’t load custom C++ ops
它通常是由PyTorch和torchvision版本不兼容引起的。需要确保当前安装的PyTorch和torchvision版本是兼容的
但是我在python中运行如下代码:
1 | |
显示结果为:
1.11.0
0.12.0
是正确对应的结果,但是就是无法使用
然后我搜了一下网上的资料,说需要重新配置pytorch,然后使用命令将pytorch删除干净。
1 | |
1 | |
都执行了一遍,自认为是卸载干净了。
根据pytorch官网找到的torch,torchvision,torchaudio的指令进行pip安装,然后发现与之前的安装相比,好像多出来了一些东西,可能是因为之前下载未关闭VPN,导致下载的版本不相互匹配或者甚至无法使用的关系吧。
然后再运行代码查看一遍torch和torchvision版本
1 | |
虽然是换了一个1.12的版本进行使用,但确确实实比之前的多出了cu113,但感觉区别不是很大(还未进行探究),总之问题解决了。
openSSL与urllib不匹配
这个错误是由于使用的urllib3版本不兼容您当前的OpenSSL版本所引起的。
但是我在cmd的查询和在虚拟环境中的查询都显示我所使用的openssl版本为1.1.1,但代码运行的报错提醒为1.1.0,目前尚未解决。
根据网上的说法,我发现可能是之前卸载torch的时候没卸载干净,因为我换成1.12进行使用,而之前的cuda为1.11版本,我认为极有可能是这个原因导致电脑中有2个openssl存在,而python使用的是之前存在的1.1.0版本的openssl库。
网上的说法是需要重新配置python编译器,使用./configure来实现配置:
1 | |
其中的/path/to/openssl是openssl的路径。
但由于我使用的是虚拟环境,虽然使用where openssl找出了2个不同版本的openssl库所在的位置,无法使用configure重新配置虚拟的python环境(因为我不会,切换到虚拟环境目录下之后,会提示configure不是指令等错误)然后我又尝试直接复制黏贴,暴力地替换openssl,但是还是没有效果
最后,我使用了另外一种解决方案:
既然openssl不知怎么修改,我改变策略对urllib进行了修改
降低urllib版本为1.25.11版本,使其能够使用1.1.0版本的openssl文件
1 | |
然后问题解决了